
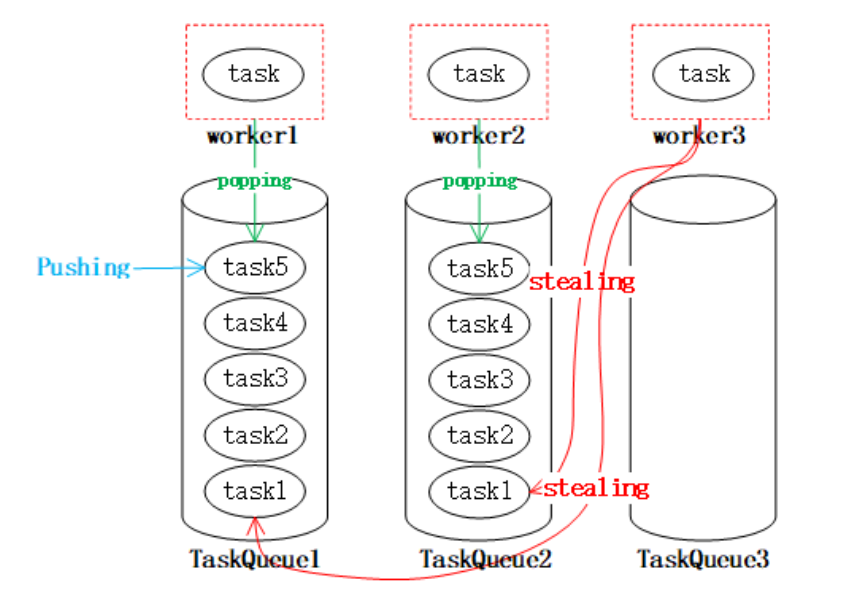
work-stealing 工作窃取算法
一种多线程和并行计算中的负载平衡策略,主要在 Java 的 Fork/Join 框架中得到应用。其基本思想是允许线程在完成其任务后从其他线程中“窃取”工作。工作窃取策略允许这些完成得快的线程去“窃取”其他线程的工作,从而尽可能均衡地利用所有可用的计算资源。
实例
使用 LinkedBlockingDeque 双端队列来实现
JDK1.7 引入的 Fork/Join 框架
false sharing 伪共享
https://zhuanlan.zhihu.com/p/65394173
当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
避免伪共享的干扰:
在独立的变量之间加 7 个 long 类型变量。
使用注解
@sun.misc.Contended,且 JVM 参数-XX:-RestrictContended
实例
ConcurrentHashMap#CounterCell,加了注解
JUC 包下的 ForkJoinPool、Striped64 (Cell 加了 注解 )的子类 LongAdder、DoubleAdder 等。
ForkJoinPool
https://sunnyday0426.blog.csdn.net/article/details/123206215
分治法
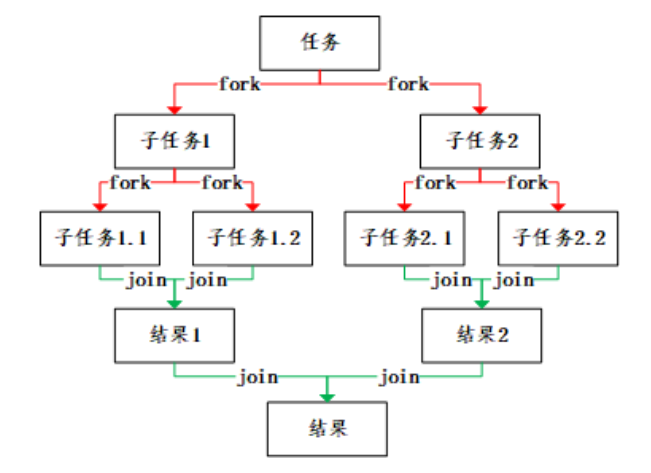
ForkJoinTask
RecursiveAction
用于计算递归操作,它不返回任何值。
RecursiveTask
用于计算递归操作,它有返回值。
map-reduce
ForkJoinPool
在我们的 Java 代码内部实现中,很多地方默认线程池都是使用的 Fork Join,比如:parallelStream、CompletableFuture;也就是说,由于多处在使用共同的线程池 ForkJoin,所以,我们普通的并行流或者 CompletableFuture 执行效率可能会受其他地方的影响。
ForkJoin CommonPool,它默认的线程数量就是你的处理器数量 -1 (至少为1),这个值是由Runtime.getRuntime().availableProcessors() 得到的。
但是可以通过系统属性 java.util.concurrent.ForkJoinPool.common. parallelism 来改变线程池大小:
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism","12");这是一个全局设置,因此它将影响代码中使用 ForkJoin 线程池的方法。
parallelStream
java8 集合 parallelStream 的出现,让我们多线程开发便捷了不少。使用 parallelStream 可以轻易的将我们的串行化集合元素处理转变为多线程处理,免受代码串行化与阻塞之苦,进而提升我们的接口执行响应速度。
java.util.stream.FindOps.FindOp
java.util.stream.ForEachOps
java.util.stream.MatchOps.MatchOp
java.util.stream.ReduceOps.ReduceOp并行流的底层是采用 ForkJoin commonPool 线程池来实现的。
CompletableFuture
记一次生产中使用 CompletableFuture 遇到的坑
异步
使用Future获得异步执行结果时,要么调用阻塞方法get(),要么轮询看isDone()是否为true,这两种方法都不是很好,因为主线程也会被迫等待。
从 Java 8 开始引入了CompletableFuture,它针对Future做了改进,可以传入回调对象,当异步任务完成或者发生异常时,自动调用回调对象的回调方法。
我们以获取股票价格为例,看看如何使用CompletableFuture:
public class CompletableFutureDemo1 {
public static void main(String[] args) throws Exception {
// 创建异步执行任务:
CompletableFuture<Double> cf = CompletableFuture.supplyAsync(CompletableFutureDemo1::fetchPrice);
// 如果执行成功:
cf.thenAccept((result) -> System.out.println("price: " + result));
// 如果执行异常:
cf.exceptionally((e) -> {
e.printStackTrace();
return null;
});
System.out.println("主线程没有被阻塞!");
// 主线程不要立刻结束,否则 CompletableFuture默认使用的线程池会立刻关闭:
Thread.sleep(6000);
}
static Double fetchPrice() {
try {
Thread.sleep(2000);
} catch (InterruptedException ignored) {
}
if (5 > 1) {
throw new RuntimeException("fetch price failed!");
}
return 5 + Math.random() * 20;
}
}可见CompletableFuture的优点是:
异步任务结束时,会自动回调某个对象的方法;
异步任务出错时,会自动回调某个对象的方法;
主线程设置好回调后,不再关心异步任务的执行
链式调用
CompletableFuture.supplyAsync(actionA).whenComplete((res, ex) -> Sout("执行完毕,结果为" + res + " 异常为" + ex)
任务执行完毕后自动调用,不管有没有抛异常都会调用
CompletableFuture.supplyAsync(actionA).thenRun(actionB)
执行任务A完成后接着执行任务B,但是任务B不需要A的结果,并且执行完任务B也不会返回结果,抛了异常不会调用
CompletableFuture.supplyAsync(actionA).thenAccept(actionB)
执行任务A完成后接着执行任务B,而且任务B需要A的结果,但是执行完任务B不会返回结果,抛了异常不会调用
CompletableFuture.supplyAsync(actionA).thenApply(actionB)
执行任务A完成后接着执行任务B,而且任务B需要A的结果,并且执行完任务B需要有返回结果,抛了异常不会调用异常处理
异常捕获
public CompletableFuture<T> exceptionally(Function<Throwable, ? extends T> fn)只消费前面任务中出现的异常信息,具有返回值;如果某一个任务出现异常被
exceptionally捕获到则剩余的任务将不会再执行。异常处理
public <U> CompletableFuture<U> handle(BiFunction<? super T, Throwable, ? extends U> fn)消费前面的结果及异常信息,具有返回值,不会中断后续任务;出现异常也可以接着往下执行,根据异常参数做进一步处理,可以为之前出现异常无法获得的结果进行重新赋值。
串行执行
如果只是实现了异步回调机制,我们还看不出CompletableFuture 相比Future的优势。CompletableFuture更强大的功能是,多个CompletableFuture可以 串行执行,例如,定义两个CompletableFuture,第一个CompletableFuture根据证券名称查询证券代码,第二个CompletableFuture根据证券代码查询证券价格,这两个CompletableFuture实现串行操作如下:
public class CompletableFutureDemo2 {
public static void main(String[] args) throws Exception {
// 第一个任务:
CompletableFuture<String> cfQuery = CompletableFuture.supplyAsync(() -> queryCode("中国石油"));
// cfQuery成功后继续执行下一个任务:
CompletableFuture<Double> cfFetch = cfQuery.thenApplyAsync(CompletableFutureDemo2::fetchPrice);
// cfFetch成功后打印结果:
cfFetch.thenAccept((result) -> System.out.println("price: " + result));
// 主线程不要立刻结束,否则 CompletableFuture默认使用的线程池会立刻关闭:
Thread.sleep(2000);
}
static String queryCode(String name) {
try {
Thread.sleep(100);
} catch (InterruptedException ignored) {
}
return "601857";
}
static Double fetchPrice(String code) {
try {
Thread.sleep(100);
} catch (InterruptedException ignored) {
}
return 5 + Math.random() * 20;
}
}并行执行
除了串行执行外,多个CompletableFuture还可以并行执行。
例如,我们考虑这样的场景:同时从新浪和网易查询证券代码,只要任意一个返回结果,就进行下一步查询价格,查询价格也同时从新浪和网易查询,只要任意一个返回结果,就完成操作:
public class CompletableFutureDemo3 {
public static void main(String[] args) throws Exception {
// 两个 CompletableFuture执行异步查询:
CompletableFuture<String> cfQueryFromSina = CompletableFuture.supplyAsync(
() -> queryCode("中国石油", "https://finance.sina.com.cn/code/"));
CompletableFuture<String> cfQueryFrom163 = CompletableFuture.supplyAsync(
() -> queryCode("中国石油", "https://money.163.com/code/"));
// 用 anyOf合并为一个新的 CompletableFuture:
CompletableFuture<Object> cfQuery = CompletableFuture.anyOf(cfQueryFromSina, cfQueryFrom163);
// 两个 CompletableFuture执行异步查询:
CompletableFuture<Double> cfFetchFromSina = cfQuery.thenApplyAsync(
(code) -> fetchPrice((String) code, "https://finance.sina.com.cn/price/"));
CompletableFuture<Double> cfFetchFrom163 = cfQuery.thenApplyAsync(
(code) -> fetchPrice((String) code, "https://money.163.com/price/"));
// 用 anyOf合并为一个新的 CompletableFuture:
CompletableFuture<Object> cfFetch = CompletableFuture.anyOf(cfFetchFromSina, cfFetchFrom163);
// 最终结果:
cfFetch.thenAccept((result) -> System.out.println("price: " + result));
// 主线程不要立刻结束,否则 CompletableFuture默认使用的线程池会立刻关闭:
Thread.sleep(200);
}
static String queryCode(String name, String url) {
System.out.println("query code from " + url + "...");
try {
Thread.sleep((long) (Math.random() * 100));
} catch (InterruptedException ignored) {
}
return "601857";
}
static Double fetchPrice(String code, String url) {
System.out.println("query price from " + url + "...");
try {
Thread.sleep((long) (Math.random() * 100));
} catch (InterruptedException ignored) {
}
return 5 + Math.random() * 20;
}
}除了anyOf()可以实现“任意个CompletableFuture只要一个成功”,allOf()可以实现“所有CompletableFuture都必须成功”,这些组合操作可以实现非常复杂的异步流程控制。
最后我们注意CompletableFuture API 的命名规则:
xxx():表示该方法将继续在已有的线程中执行;xxxAsync():表示将异步在线程池中执行。
Java8 提供的CompletableFuture 可以自定义线程池或使用默认线程池对数据进行异步处理,且可以根据需求选择是否返回异步结果!灵活的使用CompletableFuture可以让我们感受 java8 的异步编程之美!
静态工厂方法
CompletableFuture的思想:当被调用时,它们会立即被安排启动开始执行异步任务(与流式操作中的延迟计算有着明显区别)。
get 与 join 的区别
CompletableFuture 使用 supplyAsync 来执行异步任务的话,可通过调用 get 或 join 方法便可获取异步线程的执行结果。
不同:get 方法抛出的是检查异常,必须用户 throw 或者 try/catch 处理;而 join 返回结果,抛出未检查异常。
相同:join 和 get 方法都是依赖于完成信号并返回结果 T 的阻塞方法。(阻塞调用者线程,等待异步线程返回结果)。
注意: CompletableFuture 的 get 方法有重载,还有一个可传入获取结果等待时间的 get 方法,如果超过等待时间,异步线程还未返回结果,那么 get 调用者线程则会抛出TimeoutException 异常。
parallelStream 与 CompletableFuture 的选择
测试案例:
每个耗时任务执行时间为 1s,本地测试机器处理器数量为 8 :
可以看到:任务数等于 CPU 核心数的情况下:对于同一个 fork-join-commPool 线程池, completableFuture 比 parallerStream 少了一个调用者线程(比如 Main 线程)!故此效率低于 parallerStream!
结论如下:
(1)如果你进行的是计算密集型的操作,并且没有 I/O,那么推荐使用 Stream 接口,因为实现简单,同时效率也可能是最高的(如果所有的线程都是计算密集型的,那就没有必要创建比处理器核数更多的线程)。
(2)反之,如果你并行的工作单元还涉及等待 I/O 的操作(包括网络连接等待),那么使用 CompletableFuture 灵活性更好,你可以依据等待/计算,或者 W/C 的比率设定需要使用的线程数。这种情况不使用并行流的另一个原因是,处理流的流水线中如果发生 I/O 等待,流的延迟特性会让我们很难判断到底什么时候触发了等待。
